Finally we have come to the point where we have started using Docker containers in our production systems. We have already used the lightweight container platform for smaller applications and now we have rolled it out for our flagship product in production as well.
A couple of days ago we had a internal brown-bag-lunch showing off what we have achieved so far. Both teams have been involved in discussing the new infrastructure and now we have rolled it out for 10% of our users. The following days we will monitor the new instance and hopefully ramp up to 100% load.
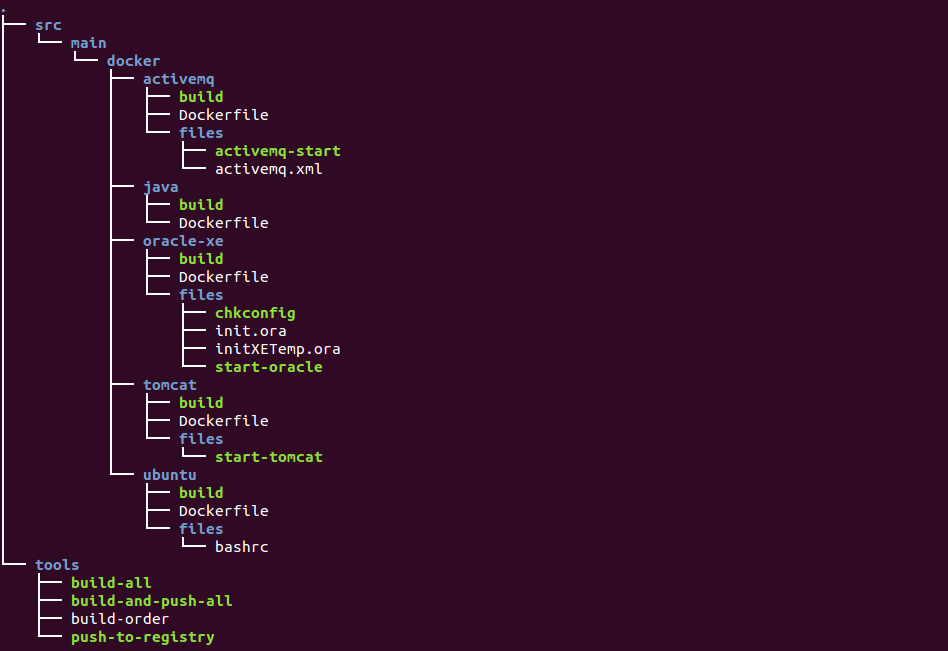
The primary incentive for containerizing our production environment was to achieve zero-downtime deployments. As we were keen on moving away from the old production environment, creating yet another Tomcat instance was not an option.
By using Docker we have drastically changed our production environment. It now has the following nice characteristics.
Everything is version-controlled
We now have fine grained control and history of how our production environment changes over time. Also, we know where to look when a question comes up about our production environment; our source code repository. A new employee can easily understand and gain an overview of the production environment setup.
Light-weight environments
Docker containers are really fast to spin up and a container does not consume the same amount of resources as a plain old VM with Guest OS. This enables us to create small and designated containers with a single purpose, as opposed to our old production environment where all services run on the same machine. “Separation of Concerns” ftw!
Reproducible production environment
Since an image is portable and guaranteed to work the same way whichever host it is running on, we can easily reproduce the production environment. This eliminates a lot of uncertainties that are present when you troubleshoot a production error.
Next steps
Using Docker in production is an important milestone. More importantly, it enables us to proceed with many other improvements.
Continuous Integration build
We are starting to make use of commands we created to automatically build and push Docker images on CI (We are trying out Bamboo).
mvn clean install -PbuildDockerImage,pushDockerImage
Our build runs a lot of integration tests that require an Oracle database. Using Docker, we are able to spin up an Oracle container on start, run our build (including integration tests) and finally stop the database container in three well defined steps in our build cycle.
Deployment tool
We are in the middle of developing a new deployment tool, called “Haddock”. It will help us automate a lot of deployment steps that we currently perform manually. Haddock takes a tag of the image we want to release, communicates with the Docker daemon on the host we want to spin up a new production instance and asks the Service Locator to direct traffic to it. We are in the middle of extracting some logic from our proxy into a service locator like app. The proxy will only direct new traffic to the new instance since we need sticky sessions for our running clients. When all client sessions have expired, we can remove the old instance from production without downtime for users.
We are really excited about our new production environment we can not wait to start utilizing our new infrastructure for a Continuous Deployment scenario. This is just the beginning…



Recent Comments